
Si les références bibliographiques ont été largement étudiées d'un point de vue quantitatif, les études, à grande échelle, du contexte dans lequel les articles sont cités sont relativement récentes.
 De la bibliométrie
De la bibliométrie
[CONSULTER LA CARTE]
Au cours des soixante dernières années, les études bibliométriques se sont principalement intéressées aux références citées dans les bibliographies des articles scientifiques. Pourtant les citations ne sont pas toutes égales! Et si les références bibliographiques ont été largement étudiées d'un point de vue quantitatif, les études, à grande échelle, du contexte dans lequel les articles sont cités sont relativement récentes, puisqu’elles nécessitent l’accès au texte intégral des articles en format électronique, ainsi que la création d’outils informatiques dédiés à cette tâche.
À partir d’un jeu tiré de sept revues de la Public Library of Science (PLOS), nous présentons ici une visualisation des verbes et du contexte linguistique associé aux travaux cités, dans le but de mieux comprendre comment les auteurs citent d'autres travaux dans les différentes sections d'une publication.
Notre protocole est le suivant. Pour chaque article disponible en plein texte :
- a) nous segmentons le corpus en phrases;
- b) nous identifions les phrases contenant une ou plusieurs références bibliographiques;
- c) et nous recherchons les verbes présents dans ces phrases.
Les données :
- Les données utilisées dans cette étude sont des articles de recherche publiés par les sept revues de la Public Library of Science (PLOS). Nous avons utilisé l'ensemble des articles publiés jusqu'au mois d’octobre 2012, pour un total d’environ 45 000 articles comptant 197 000 sections. Environ 87% des articles proviennent des domaines de la biologie et de la médecine, et le reste couvre un large éventail de domaines : sciences de l'information, physique, sciences sociales, etc.
L'hypothèse
L’une de nos hypothèses de travail est que les verbes utilisés dans le contexte des références bibliographiques est porteur d’une information sémantique sur la nature de la relation, sur l’usage des citations ainsi que sur les motivations des auteurs citant ces travaux. De plus, nos travaux s’intéressent également aux verbes dans un cadre rhétorique et, plus particulièrement, à la structure dite « IMRaD – Introduction, Méthodes, Résultats et Discussion » des publications.
La structure IMRaD a été adoptée par une grande partie des journaux au milieu du XXe siècle, et elle est devenue le standard dans les années 1970. Elle introduit un cadre rhétorique qui a pour but de faciliter la lecture et de fournir un accès rapide à l'information, car il normalise la structure argumentative. La séquence IMRaD fournit donc la structure de l'écriture scientifique, divisant les articles en quatre sections, chacune ayant une fonction rhétorique spécifique.
Le traitement
Dans un premier temps, et afin de pouvoir déterminer la position de chaque référence présente dans le texte par rapport à la structure IMRaD des articles, nous avons identifié les différentes sections de chaque article – Introduction, Méthodes, Résultats et Discussion. L’analyse des titres de section nous a permis d’associer la section à la structure rhétorique.
Pour chaque section, nous avons calculé la taille de celle-ci – en nombre de phrase la constituant – ainsi que le nombre et la position des références. L’un des résultats les plus intéressants est que si nous prenons en considération la structure IMRaD des articles de PLOS, nous constatons une invariance de la distribution des références. De plus, cette dernière de dépend pas de la nature des revues présentes dans PLOS1. Ce premier résultat a montré qu'il existe une relation forte entre la structure IMRaD et les références présentes dans les écrits scientifiques.
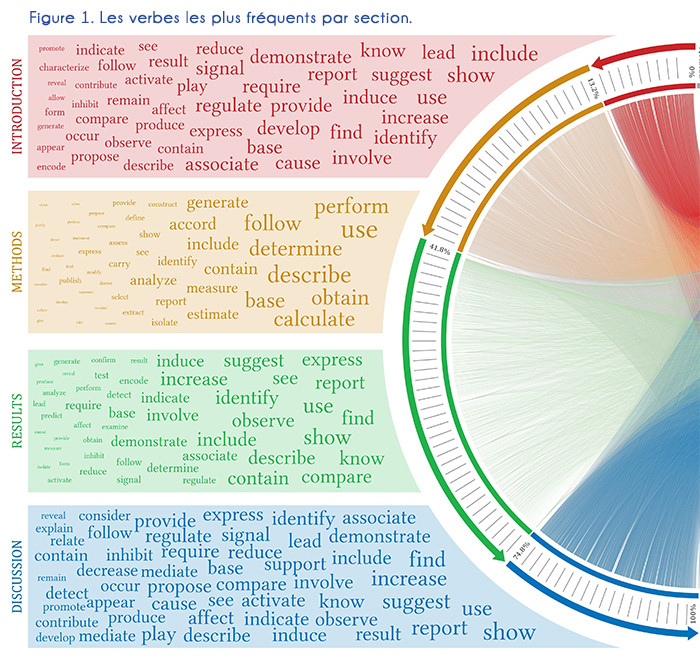
Dans un second temps, nous avons observé les occurrences des verbes présents dans les phrases contenant des références en fonction de chacune des sections. À partir des 1 807 verbes identifiés, nous avons constaté que seulement 500 d'entre eux représentaient 90% de tous les contextes de citation4. Pour la visualisation, nous avons utilisé les 87 verbes les plus fréquents qui représentent environ 60% de tous les contextes de citation [2, 3].
La figure 1 présente les verbes les plus fréquents des quatre sections, en haut à gauche de la représentation circulaire. En montrant la fréquence d’utilisation des verbes dans chacune des quatre sections de l’article, nous illustrons le fait que la manière de présenter une référence bibliographique dans le texte dépend fortement de la position de celle-ci dans l’article. Ainsi, les résultats indiquent clairement que la structure rhétorique des articles scientifiques détermine les endroits où sont positionnés les références mais aussi la manière dont elles sont mises en relation avec l’article lui-même. Par exemple, s’il est naturel de trouver une forte concentration de références en introduction (état de l’art), connaitre les verbes les introduisant est une étape essentielle vers l'analyse lexicale et sémantique des contextes de citation.
Le rôle de la cartographie
[CONSULTER LA CARTE DONT SONT TIRÉS LES FIGURES 1 ET 2]
Le tableau 2 montre les listes ordonnées des dix verbes les plus fréquents dans les quatre types de section. On y observe que chacune section contient une répartition de verbes avec des densités qui lui sont propres. Par exemple, l’Introduction montre une grande diversité dans les verbes utilisés tandis que la Méthode utilise un petit nombre de verbes (use, describe, obtain, calculate, perform) avec des fréquences très élevées. Aussi, chaque verbe peut être observé indépendamment et analysé par rapport aux sections dans lesquelles il apparaît. Par exemple, le verbe show apparaît au sein des différentes sections avec une très haute fréquence sauf dans la section Méthode, alors que le verbe describe est plus fréquent dans les sections Méthode et Discussion et ne se retrouve que très rarement dans les deux autres sections. Ces résultats confirment que les auteurs utilisent différents verbes pour introduire les références selon leur position dans la structure rhétorique et de ce fait, ces positions sont un facteur important pour l'analyse de l’usage des citations.

L'arbre contextuel montre les contextes dans lesquels le verbe apparaît. De telles représentations peuvent être utilisées pour analyser les différentes valeurs sémantiques du verbe selon le contexte. La figure 2 présente une visualisation des contextes du verbe observe, qui est l'un des plus utilisés dans les sections Résultats et Discussion. Par exemple, le premier type de contexte contient not et est utilisé par les scientifiques pour indiquer des observations qui diffèrent des travaux précédents. Un premier pas vers l’étude de la citation négative…

Les perspectives
Ces résultats montrent que les références jouent un rôle différent en fonction de leur position dans la structure rhétorique des articles scientifiques. Du point de vue de la bibliométrie, cette carte montre clairement que les sections d’un article doivent être prises en compte dans l’analyse des contextes de citation. Comprendre l’utilisation des références en tant que fonction est une étape essentielle, nous seulement d’un point de vue bibliométrique mais aussi en recherche d’information avec des applications directes de fouille textuelle pour les projets en humanités numériques.
Références :
- 1. Marc Bertin, Iana Atanassova, Vincent Larivière, & Yves Gingras. (2015, à paraître). The Invariant Distribution of References in Scientific Articles. Journal of the Association for Information Science and Technology (JASIST).
- 2. Marc Bertin, Iana Atanassova, Vincent Larivière, & Yves Gingras. (2015). Mapping the Linguistic Context of Citations. Bulletin of the Association for Information Science and Technology (ASIS&T) featuring the “The Future of Science Mapping”, December/January 2015, vol. 41, No. 2
- 3. Marc Bertin, Iana Atanassova, Vincent Larivière, & Yves Gingras. (2014), The Linguistic Context of Citations. 10th Iteration of the Places & Spaces: Mapping Science Exhibit on “The Future of Science Mapping”
- 4. Marc Bertin & Iana Atanassova. (2014). A study of lexical distribution in citation contexts through the IMRaD standard. Proceedings of the First Workshop on Bibliometric-enhanced Information Retrieval co-located with 36th European Conference on Information Retrieval (ECIR 2014), 1143: 5-12, Amsterdam, The Netherlands, April 13, 2014.
- 5. Martin I Krzywinski, Jacqueline E Schein, Inanc Birol, Joseph Connors, Randy Gascoyne, Doug Horsman, Steven J Jones, and Marco A Marra. (2009). Circos: An information aesthetic for comparative genomics. Genome Res.,19(9): 1639-45: doi: 10.1101/gr.092759.109
- 6. Helmut Schmid. Probabilistic part-of-speech tagging using decision trees. (1994). In Proceedings of International Conference on New Methods in Language Processing, 12: 44–49. Manchester, UK.
- Marc Bertin, Iana Atanassova, Vincent Larivière et Yves Gingras
CIRST
Marc Bertin est titulaire d’un doctorat en Mathématiques, Informatique et Application aux Sciences de l’Homme. Il effectue ses recherches à l’Université du Québec à Montréal au sein du CIRST. Titulaire d’un Master en Traitement Automatique des Langues, il est également chercheur associé à l’Université de Paris-Sorbonne. Membre de plusieurs comités de programmes dans différents disciplines dont la recherche d’information ou la bibliométrie, ses thématiques de recherche portent sur le traitement informatique des données textuelles, l’annotation sémantique et la fouille textuelle. Ses recherches trouvent notamment des applications dans les humanités numériques.
Iana Atanassova est Maître de Conférences au Centre de Recherche en Linguistique et Traitement Automatique des Langues "Lucien Tesnière", à l’Université de Franche-Comté, France. Ses recherches portent sur l’annotation sémantique, l’extraction d’information et la recherche d’information avec des applications en traitement automatique d’articles scientifiques. Elle est titulaire d’une maîtrise en Mathématiques (Université de Sofia, Bulgarie), d’un master en Ingénierie de la langue (Université Paris-Sorbonne, France) et d’un doctorat en Mathématiques, Informatique et Applications en Sciences de l’Homme (Université Paris-Sorbonne, France).
Vincent Larivière est titulaire de la Chaire de recherche du Canada sur les transformations de la communication savante, professeur adjoint à l’École de bibliothéconomie et des sciences de l’information de l’Université de Montréal, membre régulier du CIRST et directeur scientifique adjoint de l’Observatoire des sciences et des technologies. Ses recherches portent sur les caractéristiques des systèmes de recherche québécois, canadien et mondial, et sur la transformation, dans le monde numérique, des modes de production et de diffusion des connaissances scientifiques et technologiques. Il est titulaire d’un baccalauréat en science, technologie et société (UQAM), d’une maîtrise en histoire (UQAM) et d’un doctorat en sciences de l’information (Université McGill).
Yves Gingras est professeur à l’Université du Québec à Montréal (UQAM) depuis 1986. Sociologue et historien des sciences, il est aujourd’hui directeur scientifique de l’Observatoire des sciences et des technologies et titulaire de la Chaire de recherche du Canada en histoire et sociologie des sciences. Il vient de publier Sociologie des sciences dans la collection Que sais-je? des PUF.
Vous aimez cet article?
Soutenez l’importance de la recherche en devenant membre de l’Acfas.
Devenir membre


